GTID consistent reads
ProxySQL is a layer 7 database proxy that understands the MySQL Protocol. It provides high availability and high performance out of the box. ProxySQL has a rich set of features, and the upcoming version 2.0 has new exciting features, like the one described in this blog post.
One of the most commonly used feature is query analysis and query routing in order to provide read/write split.
When a client connected to ProxySQL executes a query, ProxySQL will first check its rules (configured by a DBA) and determine on which MySQL server the query needs to be executed. A minimalistic example is to send all reads to slaves, and writes to master. Of course, this example is not to be used in production, because sending reads to slaves may return stale data, and while stale data is ok for some queries, it is not ok for other queries. For this reason, we generally suggest to send all traffic to master, and thanks to the statistics that ProxySQL makes available, a DBA can create more precise routing rules in which only specific set of queries are routed to the slaves. More details and examples are available in a previous blog post.
ProxySQL routing can be customized a lot: it is even possible to use next_query_flagIN to specific that after a specific query, the next query (or the next set of queries) should be executed on a determined hostgroup. For example, you can specify that after a specific INSERT, the following SELECT should be executed on the same server. Although this solution is advanced, it is also complex to configure because the DBA should know the application logic to determine which are the read-after-write queries.
Causal consistency reads
Some application cannot work properly with stale data, but they can operate properly with causal consistency reads: this happens when a client is able to read the data that has written. Standard MySQL asynchronous replication cannot guarantee that. In fact, if a client writes on master, and immediately tries to read it from a slave, it is possible that the data is yet not replicated to slave.
How can we guarantee that a query is executed on slave only if a certain write event was already replicated?
GTID helps in this.
Since MySQL 5.7.5 , a client can know (in the OK packet returned by MySQL Server) which is the GTID of its last write, and can execute a read on any slave where that GTID is already executed. Lefred described the process in a blog post with an example: the server needs to have session_track_gtids enabled, and the client can execute WAIT_FOR_EXECUTED_GTID_SET on a slave and wait for the replication to apply the event on slave.
Although this solution works, it is very trivial and not usable in production, mostly for the following reasons/drawbacks:
- executing a query with WAIT_FOR_EXECUTED_GTID_SET before the real query will add latency before any real query
- the client doesn’t know which slave will be in sync first, so it needs to check many/all slaves
- it is possible that none of the slaves will be in sync in an acceptable amount of time (will you wait few seconds before running the query?)
That being said, the above solution is not usable in production and is mostly a POC.
Can ProxySQL tracks GTID?
ProxySQL acts as client for MySQL . Therefore, if session_track_gtids is enabled, ProxySQL can track the GTID of all the clients’ requests, and know exactly the last GTID for each client’s connection. ProxySQL can then use this information to send a read to the right slave where the GTID was already executed. How can ProxySQL track GTID executed on slaves?
There are mostly two approaches:
- Pull : at regular interval, ProxySQL queries all the MySQL servers to retrieve the GTID executed set
- Push : every time a new write event is executed on a MySQL server (master or slave) and a new GTID is generated, ProxySQL is immediately notified
No need to say, the pull method is not very efficient because it will almost surely introduce latency based on how frequently ProxySQL will query the MySQL servers to retrieve the GTID executed set. The less frequent the check, the less accurate it will be. The more frequent the check, the more precise, yet it will cause load on MySQL servers and inefficiently use a lot of bandwidth if there are hundreds of ProxySQL instances. In other words, this solution is not efficient neither scalable.
What about pull method?
Real time retrieval of GTID executed set
Real time retrieval of GTID executed set is technically simple: consume and parse binlog in real time! Although, if ProxySQL becomes a slave of every MySQL server, it is easy to conclude that this solution will consume CPU resources on ProxySQL instance. To make things worse, in a setup with a lot of ProxySQL instances, if each ProxySQL instance needs to get replication events via replication from every MySQL server, network bandwidth will soon become a bottleneck. For example, think what will happen if you have 4 clusters, and each cluster has 1 master generating 40GB of binlog per day and 5 slaves, and a total of 30 proxysql instances. If each proxysql instance needs to become a slave of the 24 MySQL servers, this solution will consume nearly 30TB of network bandwidth in 1 day (and you don’t want this if you pay for bandwidth usage).
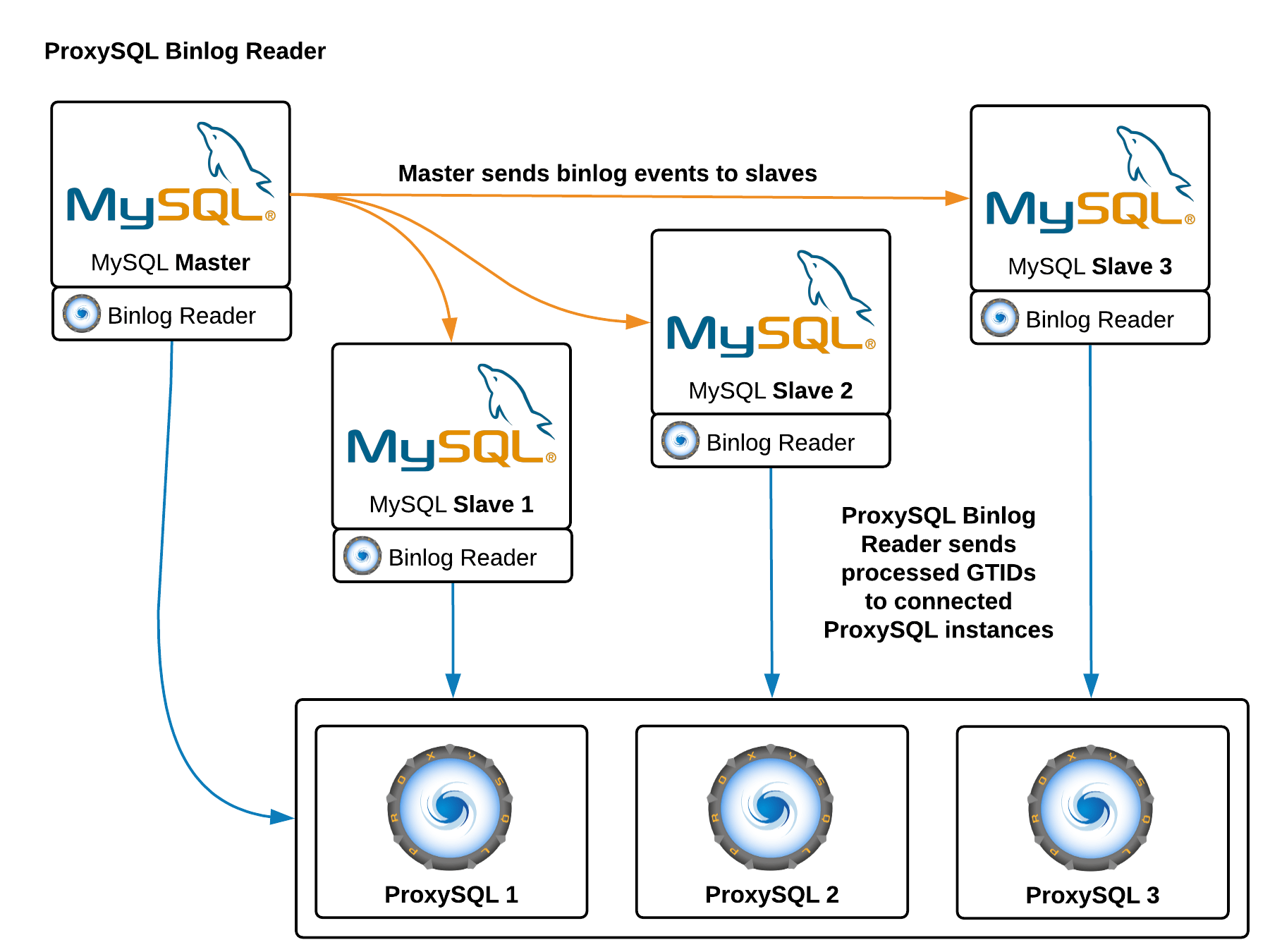
ProxySQL Binlog Reader
The pull method described above doesn’t scale and it consumes too many resources. For this reason, a new tool was implemented: ProxySQL Binlog Reader.
- ProxySQL Binlog Reader is a lightweight process that run on the MySQL server, it connects to the MySQL server as a slave, and tracks all the GTID events.
- ProxySQL Binlog Reader is itself a server: when a client connects to it, it will start streaming GTID in a very efficient format to reduce bandwidth.
By now you can easily guess who will be the clients of ProxySQL Binlog Reader: all the ProxySQL instances.
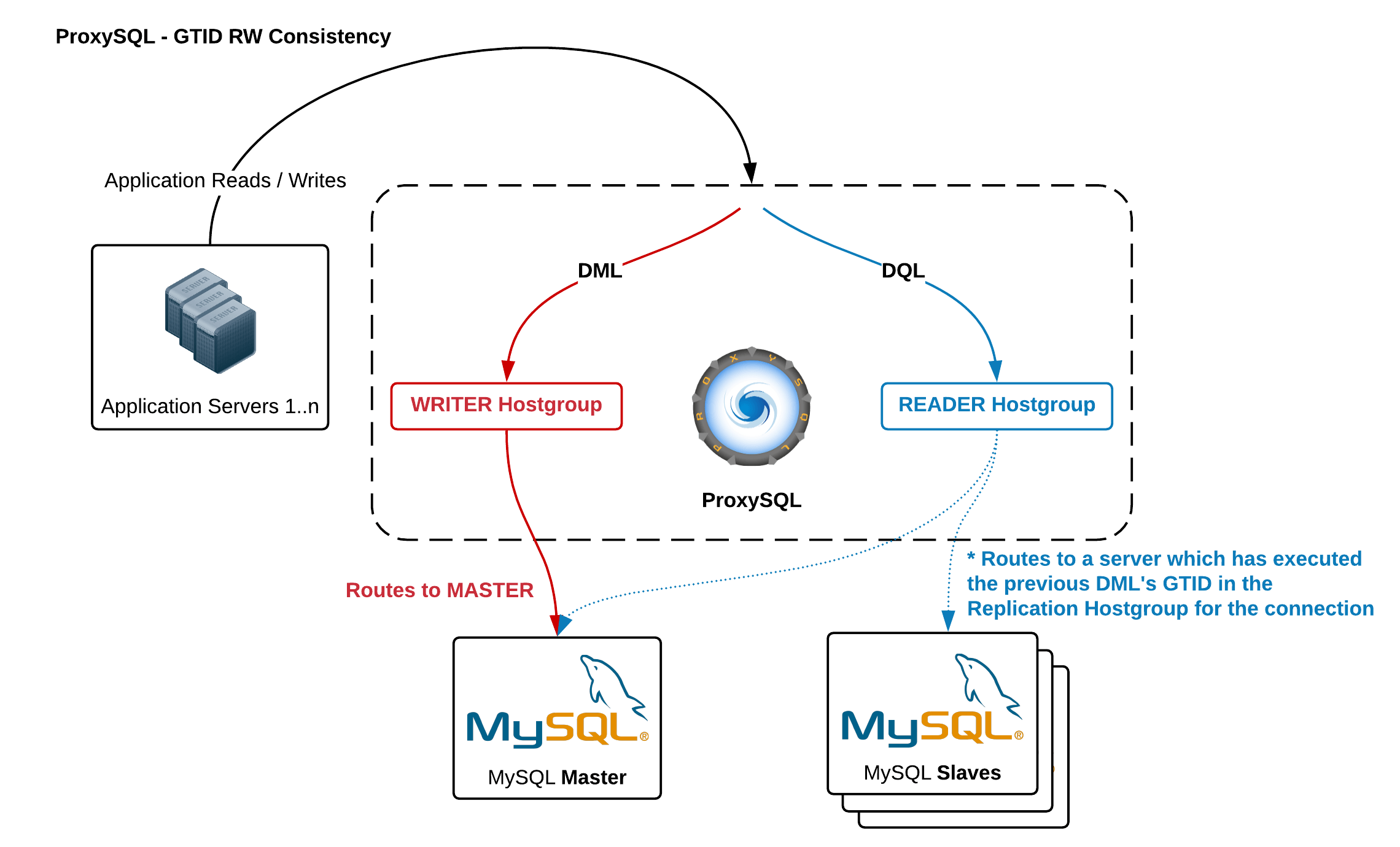
Real time routing
ProxySQL Binlog Reader allows ProxySQL to know in real time which GTID was been executed on every MySQL server, slaves and master itself. Thanks to this, when a client executes a reads that needs to provide causal consistency reads, ProxySQL immediately knows on which server the query can be executed. If for whatever reason the writes was not executed on any slave yet, ProxySQL will know that the write was executed on master and send the read there.
Advanced configuration, and support for many clusters
ProxySQL is extremely configurable, and this is true also for this feature. The most important tuning is that you can configure if a read should provide causal consistency or not, and if causal consistency is required you need to specify to which hostgroup should be consistent. This last detail is very important: you don’t simply enable causal consistency, but you need to specify that a read to hostgroup B should be causal consistent to hostgroup A. This allows ProxySQL to implement the algorithm on any number of hostgroups and clusters, and also allows a single client to execute queries on multiple clusters (sharding) knowing that the causal consistency read will be executed on the right cluster.
Requirements
Casual reads using GTID is only possible if:
- ProxySQL 2.0 is used (older versions do not support it)
- the backend is MySQL version 5.7.5 or newer. Older versions of MySQL do not have capability to use this functionality.
- replication binlog format is ROW
- GTID is enabled (that sounds almost obvious).
- backends are either Oracle’s or Percona’s MySQL Server: MariaDB Server does not support
session_track_gtids, but I hope it will be available soon.
Conclusion
The upcoming release of ProxySQL 2.0 is able to track executed GTID in real-time from all the MySQL servers in a replication topology. Adaptive query routing based on GTID tracking allows to provide causal reads, and ProxySQL can route reads to the slave where the needed GTID event was already executed. This solutions scales very well with limited network usage, and is being already tested in production environments.
Do you want to know more? Join us at Percona Live 2018 and attend our session Consistent Reads Using ProxySQL and GTID