A Beginner's Guide to Database Sharding: How to Scale Your Database Effectively

As businesses grow, so do their data needs. A small application that once handled a few users can quickly evolve into a system that supports thousands—or even millions—of transactions daily.
According to IDC, the global volume of data is predicted to reach 175 zettabytes by 2025, putting immense pressure on database systems to manage and store this data effectively. With this growth comes the challenge of managing database performance, ensuring your system can handle increased traffic and data without slowing down or crashing.
Scaling a database vertically by adding more resources (like CPU or memory) works up to a point, but even the most powerful single machine will hit its limits. This is where horizontal scaling, or distributing data across multiple servers, becomes essential. One of the most effective methods for achieving this distribution is database sharding.
What is Database Sharding?
Database sharding categorizes data across multiple databases or servers to improve performance, scalability, and fault tolerance. Sharding splits an extensive database into smaller, more manageable parts called “shards.” Each shard contains a subset of the overall data, allowing the database to distribute the load across multiple servers.
For example, a large e-commerce website handles millions of daily user transactions. Without sharding, all this data (customer details, orders, inventory) would be stored in one massive database, leading to slow response times and even system crashes. With sharding, the data is split into smaller databases—one shard could handle users with IDs from 1 to 1,000,000, while another handles users from 1,000,001 to 2,000,000, and so on.
Horizontal Partitioning (Sharding) vs Vertical Partitioning
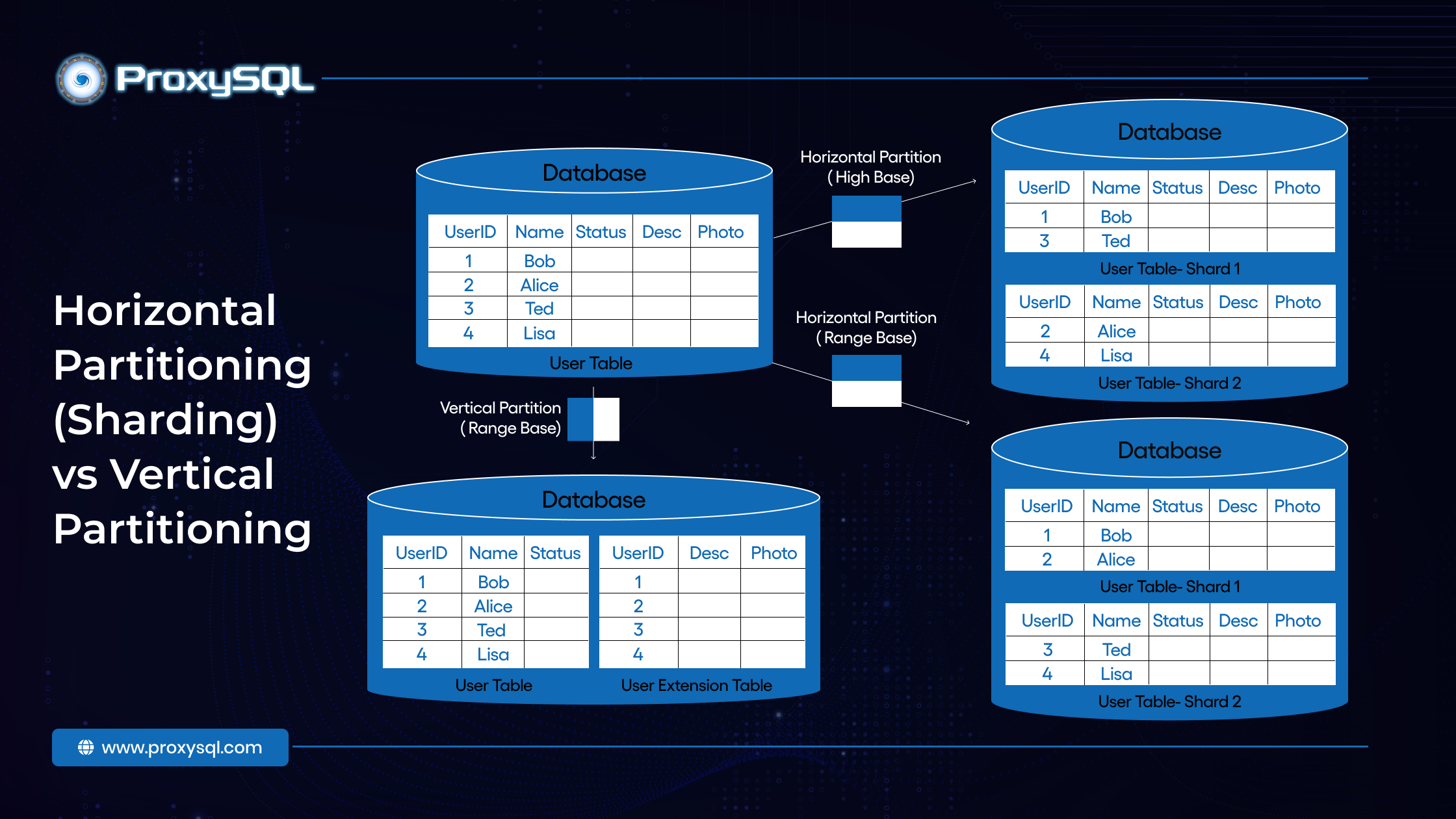
Sharding is a form of horizontal partitioning. In horizontal partitioning, rows of data are split across multiple databases or servers. Each shard holds a limited number of rows, but every shard has the same schema. For instance, if you have a customer information database, shard A might hold customers from region 1, while shard B holds customers from region 2. The application routes queries to the appropriate shard based on this distribution.
On the other hand, vertical partitioning involves splitting the database into columns instead of rows. For example, customer data might be divided so that one server stores personal details (e.g., name, contact information) while another holds financial information (e.g., account balances, transaction history). Vertical partitioning is typically more suitable for applications where specific columns are accessed more frequently than others.
Sharding vs Replication
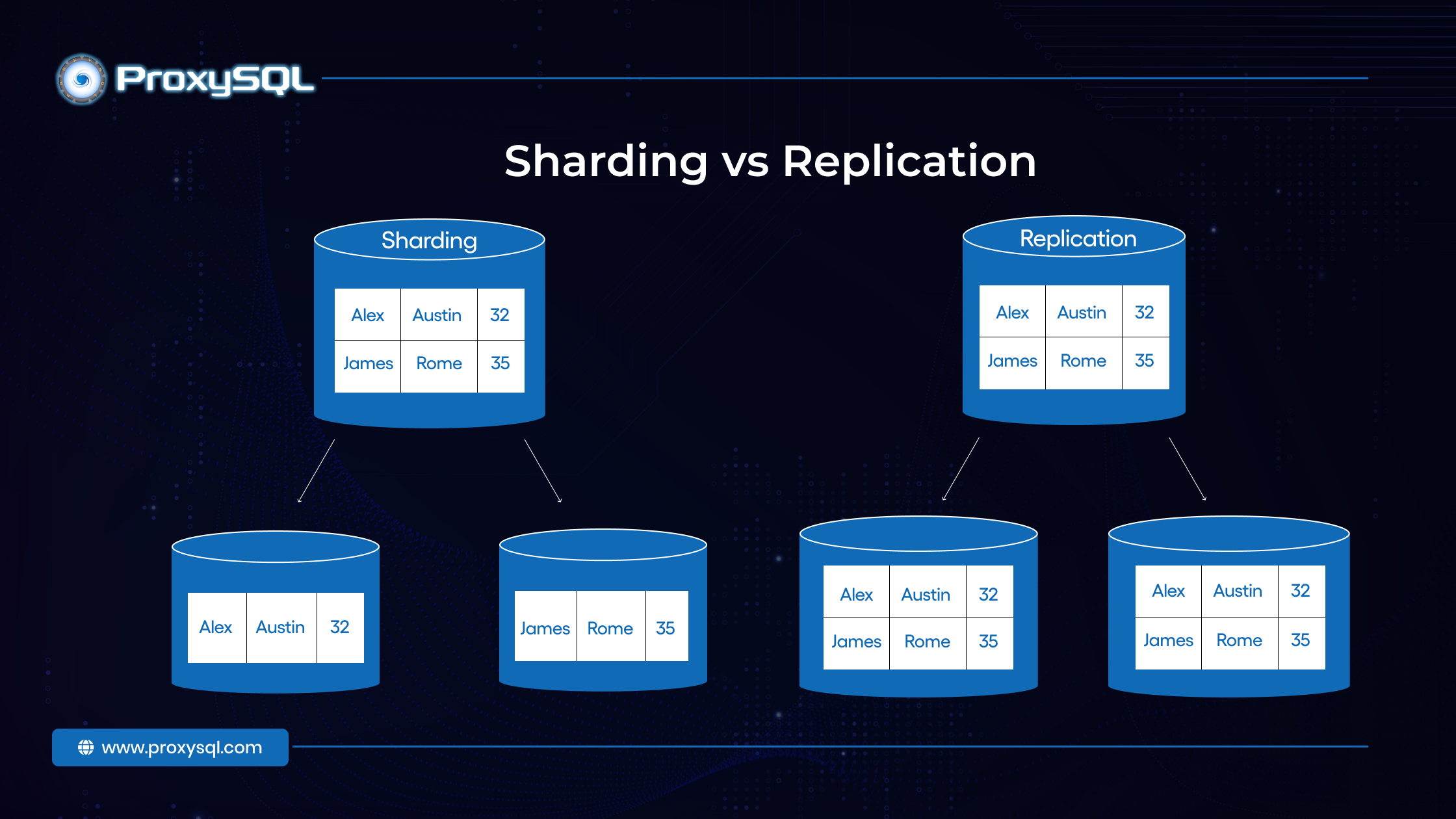
Sharding is often confused with replication, but it serves different purposes. In replication, copies of the same database are maintained on multiple servers. This approach enhances availability and redundancy; if one server fails, the system can continue running using the replicated data. However, all servers in a replicated setup still hold the same dataset, meaning replication doesn’t solve the problem of distributing data to handle heavy traffic.
Alternatively, sharding distributes unique pieces of data across different servers. Instead of duplicating the entire dataset, each shard contains only a portion. This reduces the load on each server and allows the system to scale horizontally by adding more shards as the database grows.
By using database sharding, organizations can handle larger datasets, improve query performance, and avoid bottlenecks that can occur when relying on a single database server.
Types of Sharding
Sharding comes in several forms, each with its method of dividing data across multiple servers. Choosing the correct type of sharding depends on your specific use case and your data structure. A primary concept in sharding is the shard key, a specific field or set of fields that determines how data is distributed across shards.
Here are the three primary types of sharding:
1. Range-based Sharding
Range-based sharding partitions data based on the values in a specific range of the shard key. Each shard holds a consecutive range of data. For example, if you’re sharding based on user IDs, one shard might contain users with IDs from 1 to 1,000, while another contains users with IDs from 1,001 to 2,000.
How It Works
- In this method, you define ranges for how the data will be divided across shards.
- As new data comes in, it is assigned to the shard based on its value relative to the defined range.
Example
An e-commerce platform might store customer data where each shard handles a specific geographical region or a range of order numbers (e.g., orders 1–1,000 on shard 1, 1,001–2,000 on shard 2).
| Pros | Cons |
|---|---|
| Simple and easy to implement. | Data skew can occur if some ranges grow faster than others, causing specific shards to become overloaded while others are underutilized. |
| Works well for data with naturally divisible ranges (e.g., dates or numeric IDs). | Performance issues can arise if most queries target one range, leading to uneven traffic distribution across shards. |
2. Hash-based Sharding
The system uses a hash function to distribute data evenly across all available shards in hash-based sharding. The hash function takes a value from the shard key and applies a mathematical operation to assign that record to a particular shard.
How It Works
- A hash function transforms the shard key (e.g., a user ID) into a number corresponding to one shard.
- The hash function ensures that data is evenly distributed, preventing data hotspots.
Example
If a user’s ID is 12345, the hash function might compute the hash of 12345 and assign it to the shard. This method ensures a more balanced distribution of data, regardless of the size or pattern of the incoming data.
| Pros | Cons |
|---|---|
| Ensures even data distribution across shards, reducing the risk of data skew. | It makes range queries more complex because data is spread randomly across shards. |
| Ideal for systems with high traffic and unpredictable query patterns. | Migrating data when adding or removing shards can be challenging. |
3. Directory-based Sharding
Directory-based sharding (or lookup-based sharding) uses a central directory or lookup table to track which shard holds which data. Instead of relying on a predictable rule (like ranges or hashes), the directory stores a mapping between records and shards.
How It Works
- The system maintains a lookup table that maps each record to a specific shard.
- When a query is made, the directory determines which shard holds the required data.
Example
A large organization might store customer data in multiple shards, with the directory mapping each customer to the appropriate shard based on criteria like location, user type, or purchase history.
| Pros | Cons |
|---|---|
| Flexibility in assigning data to shards, allowing for custom partitioning schemes. | The central directory adds complexity and potential for a single point of failure. |
| Easy to implement changes to the partitioning logic (e.g., reassigning a customer to a different shard). | Directory lookups can become a bottleneck if not managed efficiently. |
Top 6 Benefits of Database Sharding
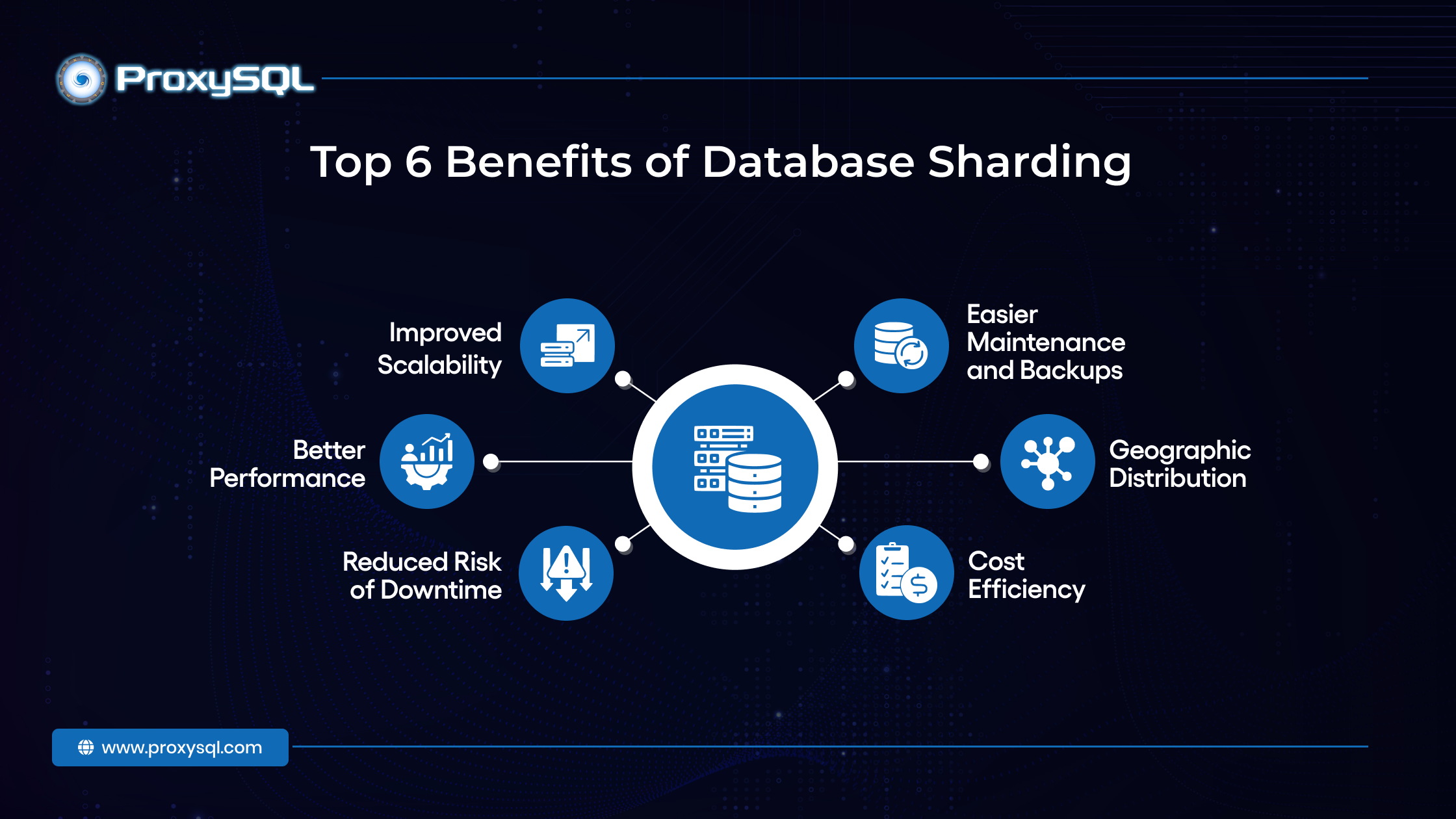
Database sharding offers several advantages, particularly for applications and systems experiencing rapid growth. Here are the benefits of implementing database sharding:
1. Improved Scalability
Adding more servers to a sharded system as your data grows is far more efficient than attempting to scale vertically by upgrading a single machine’s resources. Sharding allows you to distribute data across multiple servers, which enables horizontal scaling. This approach means that you can continue adding servers (or shards) as the volume of data increases without needing to redesign the database or infrastructure.
For example, if your application starts handling millions of users, rather than one server trying to manage all the traffic, multiple shards can divide the workload. Each shard handles a subset of the data, making the system scalable as your data grows.
2. Better Performance
With sharding, each server only needs to manage a portion of the total data, resulting in faster query performance. Since the data is spread across multiple servers, each server handles fewer queries and smaller datasets, reducing response times and quicker execution of read and write operations.
This benefit is particularly evident in large-scale applications, where a single database server would otherwise become overwhelmed by a high volume of transactions. Sharding optimizes database performance by distributing the query load, reducing bottlenecks, and minimizing system slowdowns during peak traffic.
3. Reduced Risk of Downtime
Sharding inherently improves your system’s availability and fault tolerance. In a sharded architecture, if one shard goes down, the rest of the system remains operational because only a subset of the data is affected. This localized failure makes it easier to isolate issues and avoid system-wide downtime. Recovery times are shorter because the database load is divided among multiple servers.
For example, in a non-sharded database, the failure of a single server could lead to complete service disruption. With sharding, even if one shard fails, users on other shards can still access their data, minimizing the impact of hardware failures or unexpected issues.
4. Easier Maintenance and Backups
As your database grows, maintenance tasks such as backups, indexing, and software updates can become time-consuming and resource-intensive. These tasks become more manageable with sharding since each shard can be maintained separately. Instead of backing up or keeping an extensive database, you can perform these operations on individual shards, reducing downtime and impacting user performance.
For example, instead of backing up a monolithic database with terabytes of data, you can perform backups on individual shards, each holding substantially smaller amounts of data. This allows you to back up multiple shards simultaneously without impacting the performance of the system or affecting users on other shards.
5. Geographic Distribution
Sharding also supports geographic distribution, which is particularly useful for global applications. By placing shards in different data centers or regions, you can ensure data is stored closer to users in various geographic areas. This reduces latency and improves the user experience, as queries and transactions are processed faster when they don’t have to travel long distances over the network.
For example, if your business operates in multiple countries, you can store customer data for each region in a local shard. This ensures faster access for users in that region, reducing lag and improving system responsiveness.
6. Cost Efficiency
Sharding allows you to use commodity hardware and cloud infrastructure to scale horizontally instead of investing in expensive high-performance hardware to vertically scale a single server. By distributing the data across multiple lower-cost servers, you can achieve similar or better performance at a fraction of the cost. Additionally, cloud platforms often allow for the dynamic allocation of resources, enabling you to add or remove shards as needed, optimizing performance and price.
How to Implement Database Sharding?
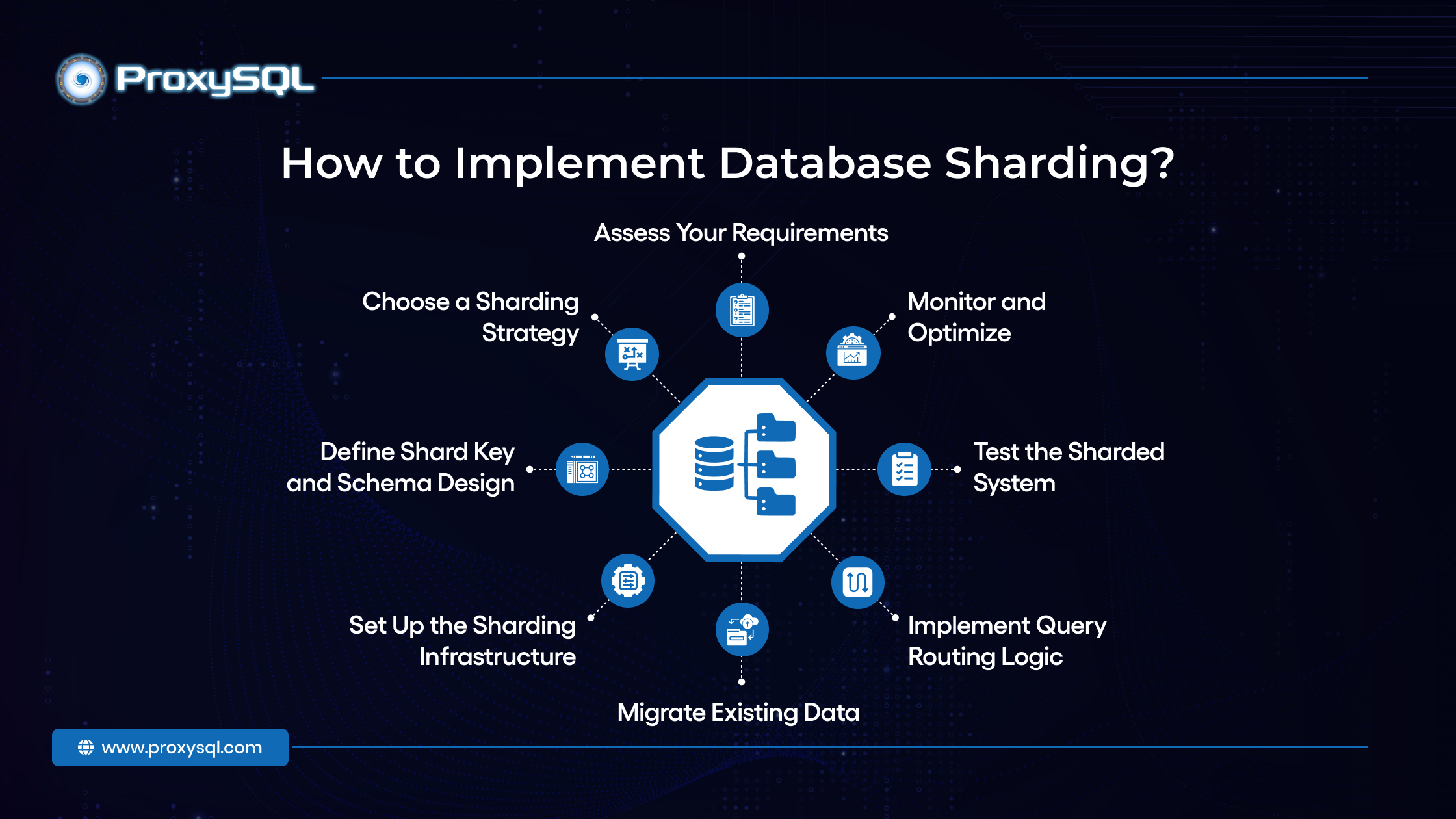
Implementing database sharding involves careful planning and execution to ensure the system remains efficient, scalable, and manageable.
1. Assess Your Requirements
Before getting into sharding, assess your application’s specific needs. Consider factors such as:
- Data Volume: Estimate the amount of data you currently have and the amount you expect to grow in the future.
- Query Patterns: Analyze how your application queries data. Are there specific fields that are frequently accessed? Do you have a mix of read and write operations?
- Performance Goals: Define your requirements, including response times and user load expectations.
Understanding these factors will help you decide the sharding strategy that best suits your application.
2. Choose a Sharding Strategy
Select a sharding strategy that aligns with your requirements. As discussed earlier, the primary strategies include:
- Range-based Sharding: Best for datasets with natural ranges (e.g., timestamps or IDs).
- Hash-based Sharding: Ideal for evenly distributing data across shards, particularly useful for unpredictable access patterns.
- Directory-based Sharding: Offers flexibility in data assignment but requires additional management overhead.
Each strategy has strengths and weaknesses, so choose the one that best suits your data characteristics and query patterns.
3. Define Shard Key and Schema Design
Once you’ve selected a sharding strategy, define the shard key, which is critical for determining how data will be distributed across shards. The shard key should:
- Allow for efficient routing of queries to the correct shard.
- Minimize cross-shard queries to improve performance.
Next, develop your database schema to support sharding. Ensure that the schema accommodates your sharding method, whether that involves modifying table structures or creating additional indexes to enhance performance.
4. Set Up the Sharding Infrastructure
Set up the necessary infrastructure with the defined strategy and schema. This typically involves:
- Provisioning Servers: Determine the number of shards and provision servers accordingly. Depending on your needs, this could be physical servers, virtual machines, or cloud instances.
- Installing Database Software: Ensure that your database management system (DBMS) supports sharding or can be configured. Some systems have built-in sharding capabilities, while others may require custom implementation.
- Implementing a Load Balancer: Consider using a load balancer to distribute incoming requests to the appropriate shards, ensuring even distribution of traffic.
5. Migrate Existing Data
If sharding an existing database, you must migrate the data into the new sharded structure. This process may involve:
- Data Export and Import: Export data from your current database into the appropriate shards based on the shard key.
- Data Validation: Ensure that the data is correctly distributed and validate the integrity of the data post-migration.
- Minimizing Downtime: Plan the migration during low-traffic periods to minimize disruption. Depending on the size of your database, you might need to use tools or scripts to handle this efficiently.
6. Implement Query Routing Logic
To ensure that queries are directed to the correct shard, implement the necessary routing logic in your application. This may involve:
- Modifying Application Code: Update your application to include logic for determining which shard to query based on the shard key.
- Using Middleware: Consider employing middleware that abstracts the sharding logic, allowing the application to interact with the database without needing to manage shards directly.
7. Test the Sharded System
Before going live, thoroughly test your sharded database to ensure everything functions as expected. Significant areas to focus on include:
- Performance Testing: Benchmark query performance across different shards to identify any bottlenecks.
- Load Testing: Simulate high traffic to observe how the system handles load and to confirm that scaling works as intended.
- Failover Testing: Test the system’s resilience by simulating server failures within a shard to ensure that the system can failover from the source instance of the shard to its replica. This ensures that the remaining replicas can continue operating without interruption. It’s important to note that failover will occur within a shard (from source to replica) rather than between different shards.
8. Monitor and Optimize
After deploying your sharded database, implement monitoring tools to track performance metrics and system health. Regularly review logs and analytics to identify areas for optimization. Essential aspects of monitoring include:
- Shard Utilization: Check that data and query loads are evenly distributed across shards.
- Response Times: Monitor query performance to ensure it meets your established goals.
- Error Rates: Keep an eye on errors during query execution or data retrieval.
Based on the insights gained from monitoring, make adjustments as necessary. This may involve redistributing data, re-evaluating your shard key, or adding additional shards as the data grows.
Best Practices for Sharding
Implementing database sharding can significantly improve your application’s scalability and performance. However, to reap these benefits, it is essential to follow best practices throughout the sharding process.
1. Choose the Right Shard Key
Selecting an appropriate shard key is one of the most critical decisions in the sharding process. The shard key determines how data is distributed across shards and can significantly affect performance. Here are some tips for choosing a good shard key:
- High Cardinality: Opt for a shard key with a high cardinality to ensure even data distribution. A low-cardinality key may lead to data skew, where one shard becomes overloaded while others remain underutilized.
- Even Distribution: Consider how your queries will access the data. Select a key that helps distribute requests evenly among shards to avoid hotspots.
- Read/Write Patterns: Analyze your application’s read and write patterns to choose a shard key that minimizes cross-shard queries, improving performance.
2. Plan for Growth
Anticipate future data growth when designing your sharded architecture. Consider the following:
- Shard Capacity: Estimate the maximum amount of data each shard will need to handle and plan accordingly. This will help you avoid performance degradation as data volume increases.
- Shard Count: Based on your expected growth, determine the optimal number of shards. Too few shards may lead to performance issues, while too many can introduce unnecessary complexity.
3. Maintain a Central Directory (if applicable)
If you use directory-based sharding, maintain an efficient and reliable central directory that maps data to shards. Important considerations include:
- Performance: Ensure the directory is optimized for quick lookups to avoid becoming a bottleneck.
- Redundancy: To enhance reliability, implement redundancy for the directory. For instance, consider using a distributed database or backup system to prevent a single point of failure.
4. Implement Load Balancing
Load balancing is crucial for ensuring that no single shard becomes overwhelmed with requests. Strategies to consider include:
- Automatic Load Balancing: Use tools or middleware that can automatically distribute traffic based on the current load on each shard.
- Regularly Review Traffic Patterns: Monitor and adjust load balancing configurations as necessary, especially during peak usage times.
5. Optimize Queries
To maximize the benefits of sharding, ensure that your queries are optimized.
- Use Shard Keys in Queries: Include the shard key in your queries whenever possible to enable direct routing to the appropriate shard. This reduces the need for cross-shard queries and enhances performance.
- Limit Cross-Shard Operations: Design your application to minimize operations that require accessing multiple shards, as these can introduce latency and complexity.
6. Plan for Data Migration
As your application evolves, you may need to migrate data between shards or rebalance data to accommodate changes in traffic patterns. Best practices for data migration include:
- Schedule Downtime: Plan data migration during low-traffic periods to minimize user disruption.
- Batch Migrations: Use batch processes to migrate data. This allows you to transfer data in chunks and maintain system responsiveness.
- Test Migration Procedures: Before performing a live migration, conduct tests to ensure the process is smooth and that data integrity is maintained.
7. Monitor Performance Regularly
Regular monitoring is essential to maintain the health of your shard database.
- Shard Load: Monitor the load on each shard to identify any imbalances or performance issues.
- Query Performance: Keep an eye on query response times and adjust configurations or optimize queries as necessary.
- System Health: Use monitoring tools to track server health, database metrics, and error rates to identify potential issues early.
8. Conduct Regular Reviews
Review your sharding strategy and effectiveness regularly. As your application grows and evolves, you may need to adjust your sharding approach based on changing requirements.
Don’t Settle for Slower Queries—Maximize Your Sharding with ProxySQL

Optimizing database performance through effective sharding is crucial for operational success. ProxySQL provides an innovative solution to enhance your sharded database architecture with intelligent query management and robust connection handling.
With ProxySQL, you get:
- Dynamic Load Balancing: Ensure efficient query distribution across your sharded MySQL servers, reducing response times and preventing overload on any single shard.
- Advanced Caching Mechanisms: Caching frequently executed queries significantly minimizes the load on your sharded databases, leading to faster access and improved user experience.
- Real-Time Monitoring: Utilize built-in metrics to track performance indicators across your shards, continuously enabling proactive adjustments and optimizations.
Integrating ProxySQL into your sharding strategy can provide unparalleled performance and reliability, allowing your applications to scale seamlessly under increased demands and complex workloads.
Are you ready to elevate your sharded database performance? Start optimizing today with ProxySQL! Learn more about how ProxySQL can enhance your sharding capabilities and transform your database infrastructure with its advanced features.
Contact us today!