ProxySQL for PostgreSQL — the failover model

Opening post in an ongoing series on ProxySQL’s role in PostgreSQL failover. This primer defines the vocabulary, the topology, and the four-phase failover model that the empirical posts measure under specific failure scenarios. Later posts assume you have read this one.
1. The problem this series answers
PostgreSQL has no built-in load balancer and no transparent client reconnect. When the primary disappears, every application’s connection pool has to discover that the old primary is gone, fail, time out, reconnect to whoever the new primary is now, re-establish session state, and try again. The application writes nothing during that window. The only number that matters operationally is how wide the window is, and how many of those failed attempts are reported back to the user as errors versus quietly retried.
ProxySQL is one of the components that can shrink that window. It sits in front of PostgreSQL, holds a stable endpoint for the application, pools and multiplexes backend connections, watches every backend with a health monitor, and re-routes traffic when an external authority decides the topology has changed. None of those properties make ProxySQL an HA tool; all of them affect how an HA-tool-driven failover looks from the application’s side.
This series is for three groups of readers. PostgreSQL DBAs running an existing HA stack — Patroni, pg_auto_failover, repmgr, RDS, Aurora — who want to know what a proxy in front of those tools changes and what it doesn’t. ProxySQL/MySQL users curious how the same model translates to PostgreSQL, where the protocol and replication semantics differ but the proxy’s job does not. Application and platform engineers responsible for “how do we not lose writes during a failover,” who need a vocabulary for talking to the database team about latency budgets and error envelopes.
The series answers three questions for each scenario it covers: where ProxySQL fits in a PostgreSQL HA stack, what it concretely contributes (and just as importantly, what it doesn’t), and how those contributions look once measured under load. The measurements use a deliberately artificial single-host lab — the numbers are relative comparisons between scenarios, not production forecasts; the §5 fairness note in every empirical post says this loudly.
What this series is not: a ProxySQL tutorial from scratch (we assume
you can edit proxysql.cnf and connect to the admin SQL port), not a
PostgreSQL replication tutorial from scratch (we assume streaming
replication and pg_ctl promote are familiar shapes), and not a
comparative benchmark of HA tools without a proxy in front of them. There
are good resources for all three; we cite the ProxySQL ones in §6.
2. ProxySQL in a PostgreSQL HA stack
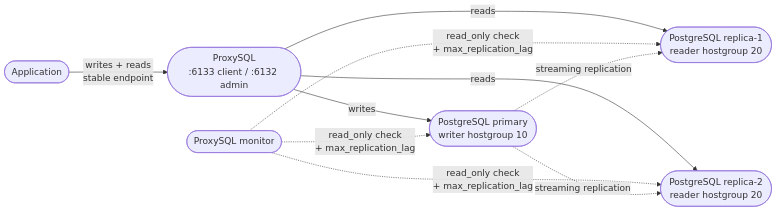
ProxySQL sits between the application and the PostgreSQL backends. It is not part of the PostgreSQL cluster. It does not own the data, it does not write WAL, it does not participate in replication, and it has no opinion about which engine version the backends run. From PostgreSQL’s point of view, ProxySQL is just another client; from the application’s point of view, ProxySQL is just another PostgreSQL endpoint. That separation is the entire point.
What ProxySQL does contribute to a failover-capable stack:
- Stable endpoint. The application connects to one address —
proxysql:6133in our labs. The proxy hides the changing identity of the writer and reader backends. No DNS update, no service-discovery refresh, no client-library reconnect to a different hostname when the writer moves between PostgreSQL hosts. - Connection pooling and multiplexing. Persistent backend connections that survive client reconnects. New client connections do not pay the per-connection handshake cost against PostgreSQL.
- Routing. Reads and writes go to different hostgroups; the proxy
enforces the split based on its routing rules — default read/write
detection plus any patterns added in
pgsql_query_rules. - Health awareness. A background monitor probes every backend on
configurable intervals — connectivity,
pg_is_in_recovery()for the writer/reader role, and replication lag. Failing backends leave the rotation; recovering ones return to it. - Configurable rerouting on signal. When the topology changes,
ProxySQL learns either explicitly (an HA tool or operator script
issues admin SQL —
UPDATE/DELETEagainstpgsql_serversplusLOAD PGSQL SERVERS TO RUNTIME) or implicitly (withpgsql_replication_hostgroupsandcheck_type='read_only', the monitor observes the newpg_is_in_recovery()answers and moves rows between hostgroups on its own).
What ProxySQL does not contribute, and where pretending otherwise gets people in trouble:
- It does not promote. No quorum, no fencing, no view of replication lag versus a global LSN. Picking the new primary is the job of Orchestrator (which we maintain and have ported to PostgreSQL), Patroni, pg_auto_failover, RDS’s control plane, an operator with a runbook, or whatever else owns the cluster. Wiring ProxySQL to make this decision invites split-brain.
- It does not heal. A dead replica stays dead until something outside ProxySQL restarts it. ProxySQL will re-add it to the pool when it comes back, but it will not start the process, reattach the data directory, or replay WAL.
- It does not preserve in-flight transactions. A transaction open on the old primary at the moment of an unplanned kill is gone. ProxySQL preserves connection identity across a failover, not transactional state.
- It does not protect against data loss. A write committed on the old primary but not yet replicated is lost. That defense lives at the PostgreSQL layer (synchronous replication or quorum-commit), not at the proxy.
ProxySQL is a visibility-and-routing layer for the application side of a failover, not the failover mechanism itself. Later posts in this series attach it to real HA tools — Patroni, pg_auto_failover, Orchestrator (which we maintain and have ported to PostgreSQL), RDS, Aurora — and measure who owns which phase. The empirical posts that come before them measure the proxy in isolation against three failure shapes, so the cost of each layer is visible separately.
3. The vocabulary
The remaining posts in this series cite the terms below. This section defines each one canonically; treat any disagreement with later posts as a bug here.
Hostgroups. Numeric identifiers grouping backends by role. This
series uses writer hostgroup 10 for the current primary and
reader hostgroup 20 for the replicas. The numbers are arbitrary;
the pairing — declared through pgsql_replication_hostgroups — is
what matters. A backend’s hostgroup membership is data on a row in
pgsql_servers; “promoting” a replica from ProxySQL’s perspective is
just moving its row from hg 20 into hg 10.
pgsql_servers. Admin-side configuration table listing every
backend ProxySQL knows about. Relevant columns: hostgroup_id,
hostname, port, status, weight, max_replication_lag. Edits
are staged; they affect routing only after LOAD PGSQL SERVERS TO RUNTIME. That two-step pattern is what lets a multi-statement rewire
land atomically in one runtime swap.
Backend status states. pgsql_servers.status carries one of four
values. They are the vocabulary for everything that follows.
- ONLINE — accepting connections, fully in rotation. The default state for healthy backends.
- SHUNNED — ProxySQL has stopped sending new traffic to this
backend, but the row is preserved so periodic re-checks can promote
it back to
ONLINEwhen it recovers.SHUNNEDis the automatic state triggered by two distinct paths: a connection-layer error at the moment of attempted use (TCP refused, peer reset, recv() failure on a fresh connection — sub-100 ms, before any monitor cycle runs), or a monitor health-check failure (withinmonitor_read_only_interval, when the periodic probe fails). Recoverable. - OFFLINE_SOFT — operator-set state. Existing pool connections finish the work they’re doing; no new connections are handed out. This is the lever for graceful drain and is the centerpiece of the planned-switchover scenario.
- OFFLINE_HARD — operator-set state. Existing connections are dropped immediately, no drain, no new traffic. The harshest stop; appropriate when you know a backend is broken and want it out of the pool right now.
Monitor. Background process inside ProxySQL that probes every
backend on configurable intervals: connectivity,
pg_is_in_recovery() for the writer/reader role, and replication
lag. Key knob: monitor_read_only_interval (milliseconds; default
1500), which bounds how stale the monitor’s view can be. The monitor
informs the routing layer — failed probes flip a row SHUNNED; a
detected role flip moves a row between hostgroups when
pgsql_replication_hostgroups is configured. It does not decide who
should be the writer; it only reports what the backend says about
its own role.
pgsql_replication_hostgroups. Associates a writer hostgroup
with a reader hostgroup and a check_type. With
check_type='read_only', the monitor uses pg_is_in_recovery() to
decide membership: a backend reporting false belongs in the writer
hostgroup, true in the reader hostgroup. This is the
implicit-rewire path. The alternative — explicit rewire via
admin SQL — bypasses the monitor and lands the new topology in a
single LOAD PGSQL SERVERS TO RUNTIME. The unplanned-failure and
planned-switchover scenarios in this series configure the implicit
path and override it with explicit admin SQL during the inject so
the measured window doesn’t depend on monitor cadence.
max_replication_lag. A per-row threshold (in seconds, set on the
pgsql_servers row for a reader). When the monitor measures a
replica’s replication lag exceeding this value, the replica is
soft-excluded from reader-hostgroup routing until lag drops back
below the threshold. The row stays ONLINE; this is a routing
decision, not a state transition. The writer’s max_replication_lag
is conventionally set to 0 (“disable this check”). The replica
loss/lag scenario in this series measures this mechanism directly.
4. The four phases of any failover
Every failover discussed in this series — unplanned primary loss, planned switchover, replica eviction, HA-tool-managed failover, RDS multi-AZ promote — follows the same four phases in the same order. The posts use this list as a reference frame, attributing latency to phases and naming responsibilities by phase. Treat the numbering as canonical.
-
Detect. Something has to notice the failure. ProxySQL’s monitor catches connectivity loss and read-only-state changes on its
monitor_read_only_intervalcadence. An external HA tool — Patroni, pg_auto_failover, Orchestrator, an RDS or Aurora control plane — catches richer signals such as consensus loss, leader-lease expiration, and storage-layer errors. Detection latency is bounded by whichever observer is fastest. If the HA tool detects a leader failure in 200 ms but ProxySQL’s monitor only re-probes every 1500 ms, the detection bound for the application-visible window is 200 ms, provided the HA tool then tells ProxySQL. -
Decide. Some authority declares which replica becomes the new primary. This is not ProxySQL’s decision. ProxySQL has no quorum, no fencing token, no view of replication lag relative to a global LSN, no notion of which replica is most caught up. Wiring it to make this decision invites split-brain — two backends both answering as writer, with the proxy happy to route to either. The decision lives in the HA tool’s consensus protocol (Patroni’s etcd or Consul interaction, pg_auto_failover’s monitor node, Orchestrator’s topology manager, RDS’s internal control plane). Decision latency is dominated by that protocol, not by anything the proxy does.
-
Promote. The chosen replica stops being a replica and starts accepting writes. In our unmanaged labs this is
pg_ctl promote. In Patroni it is a controlled switchover orchestrated through the distributed configuration store. In RDS it is a Multi-AZ failover triggered by the AWS control plane. Promotion latency is a PostgreSQL-and-engine number — how much WAL has to be replayed, how fast the recovery handoff completes, how much warm-up the new primary has to do — and ProxySQL does not influence it. -
Rewire. ProxySQL learns that the writer for hostgroup 10 is no longer the old primary. Two paths. The explicit path: admin SQL issued by the HA tool or an operator script —
DELETE FROM pgsql_servers WHERE port=...,UPDATE pgsql_servers SET hostgroup_id=10 WHERE port=...,LOAD PGSQL SERVERS TO RUNTIME— and the new topology lands atomically. The implicit path: the monitor’s nextpg_is_in_recovery()probe sees the role flip andpgsql_replication_hostgroupsmoves the row automatically. Rewire latency is bounded bymonitor_read_only_intervalfor the implicit path; near-zero for the explicit path.
ProxySQL influences phases 1 (partially — its monitor is one observer
of many) and 4 (directly — explicit or implicit). It does not
participate in phases 2 or 3 at all. Later posts in this series attach
this model to real HA stacks and account for who owns what; the
empirical posts before them measure phases 1 and 4 in isolation, using
pg_ctl promote as a stand-in for the phase-3 cost of any real engine.
5. The series at a glance
The series is organized in two arcs. Headline numbers below come from the OBSERVED.md files of the empirical posts already published; forward-looking summaries describe the intended scope, not measurements, and new posts may be added out of order as topics warrant.
ProxySQL in isolation. The empirical posts pin one failure shape
at a time and measure the proxy’s contribution alone, with pg_ctl
standing in for the promote term:
- Surviving an unplanned primary failure.
SIGKILL the primary’s postmaster, promote a replica, rewire,
measure when writes resume. Median 1900 ms (range 1500–2100 ms),
zero pgbench errors across 1.76 M transactions over three
90-second trials. The window decomposes into a kernel-reset
drain on the killed sockets (~800 ms),
pg_ctl promote(~1100 ms), and a near-zero rewire term. - Zero-downtime planned switchover.
OFFLINE_SOFTthe primary, wait for the writer-hostgroupConnUsedto drain, promote, rewire. Median total measured window 1100 ms (range 900–1200 ms), zero errors. Of that 1100 ms, only ~200 ms was actual ok=0 disruption (the rewire blip afterpg_ctl promote); the rest was drain-poll wait, brief sleeps between polls, and promotion latency. Compared with the unplanned scenario, the planned path avoids the ~800 ms kernel-reset drain and delivers a far shorter application-visible ok=0 gap (~200 ms vs ~1100 ms). - When a replica dies (or just lags).
Two sub-experiments: SIGKILL one replica; or pause its WAL
replay so it falls behind by more than
max_replication_lag. Both sub-experiments produced no measurable disruption to read throughput (resume-time sentinel-1, zero errors). The reroute to the surviving replica happens inside one 100 ms harness sample window; the surviving replica absorbs the load.
ProxySQL alongside real HA stacks. Other posts in the series hand the detect/decide/promote loop to a real HA controller and measure ProxySQL’s role in the wider system:
- Patroni + ProxySQL. Division of responsibility between Patroni (detect/decide/promote, fence the old primary) and ProxySQL (rewire, hold the application endpoint), benchmarked against a Patroni + HAProxy baseline. Patroni + ProxySQL: 10 000 ms failover window, zero application errors. Patroni + HAProxy baseline: pgbench died on the connection cut — no measurable window. The headline isn’t “which is faster” (Patroni’s detect+promote cycle dominates either way) but “which kept the application alive”: HAProxy hard-cuts the client connection, ProxySQL maintains the pool through the swap.
- pg_auto_failover + ProxySQL. Same shape as the Patroni post, with the lighter-weight pg_auto_failover monitor model in place of Patroni’s distributed config store.
- Orchestrator + ProxySQL. Orchestrator is now maintained by the ProxySQL team and has been ported to PostgreSQL, bringing the same topology-aware discovery and failover model it pioneered in the MySQL world. A dedicated post covers the pairing and the PostgreSQL-specific behaviors.
- RDS for PostgreSQL + ProxySQL. What RDS’s single Multi-AZ endpoint can’t do — read/write split, fast in-process rewire, per-replica lag-aware routing — and what it doesn’t have to, because the control plane handles detect/decide/promote.
- Aurora PostgreSQL + ProxySQL. Cluster endpoint vs. reader endpoint, Aurora’s failover tiers, and why a proxy in front of Aurora is a different shape of question than a proxy in front of vanilla PostgreSQL or RDS.
6. What this series does not cover
Three classes of question are explicitly out of scope here.
Split-brain, fencing, and network partitions. HA-tool concerns. Who is the writer, what prevents two writers existing simultaneously, recovery from a partition that drops the wrong node — all problems the HA stack has to solve. ProxySQL is downstream; if the HA tool wedges, the proxy will route to whatever it was last told. We discuss the boundary in the HA-tool posts later in this series but do not measure the failure modes themselves.
Application-visible effects as a standalone topic. Prepared
statement survival, driver reconnect behavior, transaction isolation
across the swap, retry semantics — these surface within empirical
posts when relevant (the unplanned-primary scenario’s “zero errors
across 1.76 M transactions” reflects ProxySQL keeping the client
connection alive through the backend swap, so pgbench’s clients
blocked on recv() rather than seeing connection errors — not a
universal driver claim) but the series has no dedicated post on
driver behavior across failover.
ProxySQL as a tutorial. We assume you can read proxysql.cnf,
connect to the admin port (mysql -h 127.0.0.1 -P 6132), and run
SELECT * FROM pgsql_servers. The
ProxySQL documentation is
the right starting point if not.
Fairness caveat (repeated in every empirical post’s §5). The
labs run on a single host, with all PostgreSQL instances and
ProxySQL on 127.0.0.1. No real network, no disk contention, no
cloud control-plane latency. The numbers are relative comparisons
between scenarios on the same lab, not production forecasts. Each
post’s §6 phase-by-phase decomposition is the part that travels.
ProxySQL is free software (GPL), actively developed, and now speaks PostgreSQL with the same production discipline it brought to MySQL. If you run PostgreSQL behind any HA stack — Patroni, pg_auto_failover, Orchestrator, RDS, Aurora, or your own scripts — put ProxySQL in front of it. The rest of this series will, post by post, show you what that buys you against specific failure shapes and specific HA tools. Start with whichever scenario matches the one keeping you up at night.