The Provider Architecture — How dbdeployer Learned to Speak PostgreSQL
This is the 3rd blog post on the dbdeployer series. Please refer to our previous blog posts for more details:
- Why dbdeployer Matters to Me — and Why ProxySQL Took Over Its Maintenance
- What’s Coming to dbdeployer
When we took over dbdeployer, it was a MySQL tool. Every code path assumed mysqld, my.cnf, CHANGE MASTER TO. Adding PostgreSQL meant not just writing new code — it meant restructuring how dbdeployer thinks about databases.
This post explains the Provider architecture we designed, how PostgreSQL proved it works, and how you can extend dbdeployer for any database.
The Problem
dbdeployer v1.x had MySQL assumptions baked into every layer:
deploy single 8.0.40
→ find mysqld binary
→ run mysqld --initialize
→ generate my.sandbox.cnf
→ write start/stop scripts
→ run init_db (CREATE USER, GRANT ALL)Every step was hardcoded. If you wanted to deploy PostgreSQL instead, you’d need to fork the entire deployment flow:
deploy single 16 --provider=postgresql
→ find postgres binary
→ run initdb
→ generate postgresql.conf + pg_hba.conf
→ write start/stop scripts
→ run CREATE USER, CREATE DATABASEThe commands look similar, but everything under the hood is different: initialization, configuration, lifecycle, replication. The old codebase had no abstraction for this.
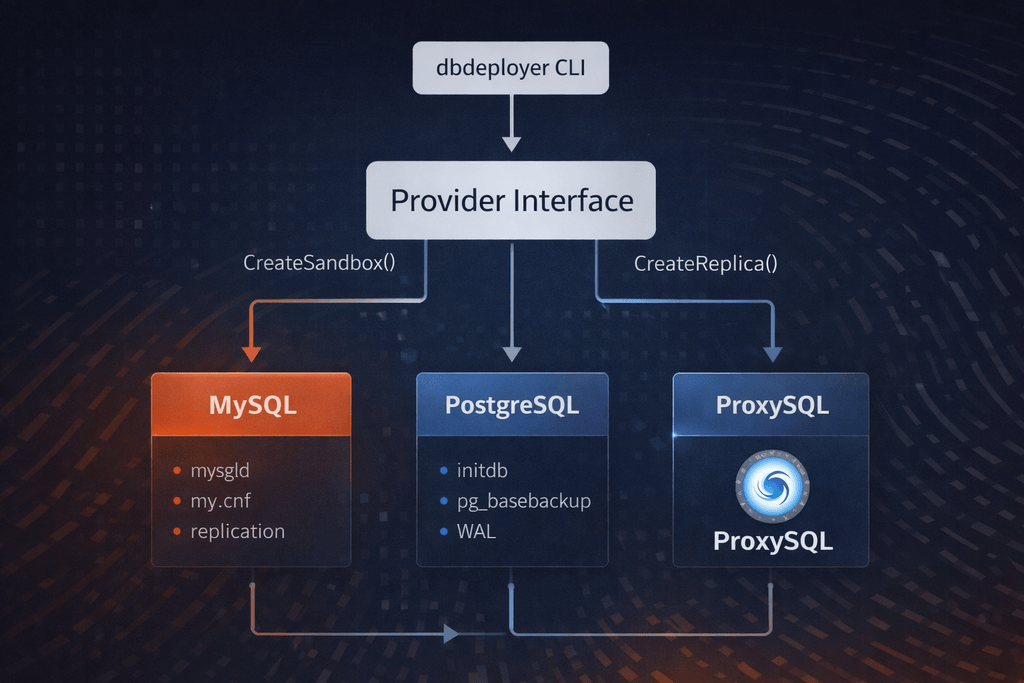
The Provider Interface
We introduced a Provider interface in providers/provider.go:
type Provider interface {
Name() string
ValidateVersion(version string) error
DefaultPorts() PortRange
FindBinary(version string) (string, error)
CreateSandbox(config SandboxConfig) (*SandboxInfo, error)
StartSandbox(dir string) error
StopSandbox(dir string) error
SupportedTopologies() []string
CreateReplica(primary SandboxInfo, config SandboxConfig) (*SandboxInfo, error)
}Each method maps to a concrete, database-specific operation:
| Method | MySQL implementation | PostgreSQL implementation |
|---|---|---|
CreateSandbox | mysqld --initialize + my.cnf + init SQL | initdb + postgresql.conf + pg_hba.conf |
CreateReplica | CHANGE REPLICATION SOURCE TO + START REPLICA | pg_basebackup + primary_conninfo |
DefaultPorts | base 3306, 3 per instance | base 15000, 1 per instance |
SupportedTopologies | single, replication, group, fan-in, all-masters, ndb, pxc | single, replication |
The key insight: the interface is about lifecycle, not configuration. Both MySQL and PostgreSQL need to initialize, start, stop, and replicate. The how differs completely. The what is the same.
The Provider Registry
Providers register themselves at startup:
// In main.go:
mysql.Register(providers.DefaultRegistry)
postgresql.Register(providers.DefaultRegistry)
proxysql.Register(providers.DefaultRegistry)Each provider’s Register() function creates an instance and adds it to the global registry:
func Register(r *providers.Registry) {
r.Register(providers.NewPostgreSQLProvider())
}The CLI uses the --provider flag to select which provider handles the command:
# MySQL (default, no --provider needed)
dbdeployer deploy single 8.4.8
# PostgreSQL
dbdeployer deploy single 16.13 --provider=postgresql
# ProxySQL
dbdeployer deploy proxysql 2.7The dbdeployer providers command shows what’s available:
$ dbdeployer providers
mysql
postgresql
proxysqlHow PostgreSQL Proved the Architecture
The PostgreSQL provider was the first real test of the interface. It’s split across multiple files:
providers/postgresql/
postgresql.go — struct, validation, port logic
sandbox.go — CreateSandbox (initdb, config generation, lifecycle scripts)
replication.go — CreateReplica (pg_basebackup, standby config)
config.go — postgresql.conf and pg_hba.conf template generation
scripts.go — start/stop/status/use script generation
unpack.go — .deb binary extraction
macos_install.go — Postgres.app binary detection for macOSCreateSandbox: initdb vs mysqld —initialize
MySQL’s initialization is a single command: mysqld --initialize --user=$USER --datadir=$DATA. It creates the system tables, generates a temporary password, and exits.
PostgreSQL’s initdb is similar in concept but different in practice:
func (p *PostgreSQLProvider) CreateSandbox(config SandboxConfig) (*SandboxInfo, error) {
basedir := p.basedirFromVersion(config.Version)
bindir := path.Join(basedir, "bin")
// 1. Create data directory
os.MkdirAll(dataDir, 0755)
// 2. Run initdb
exec.Command(path.Join(bindir, "initdb"),
"-D", dataDir, "-U", config.DbUser).Run()
// 3. Generate postgresql.conf
generatePostgresqlConf(dataDir, config)
// 4. Generate pg_hba.conf (trust-based for sandboxes)
generatePgHbaConf(dataDir, config)
// 5. Write lifecycle scripts (start, stop, status, use)
writeLifecycleScripts(dataDir, bindir, config)
return &SandboxInfo{Dir: dataDir, Port: config.Port}, nil
}The interface doesn’t care about these internals. It passes a SandboxConfig (version, port, user, password, options) and gets back a SandboxInfo (directory, port, socket, status). What happens in between is entirely up to the provider.
CreateReplica: pg_basebackup vs CHANGE REPLICATION SOURCE TO
MySQL replication setup:
CHANGE REPLICATION SOURCE TO
SOURCE_HOST='127.0.0.1',
SOURCE_PORT=22801,
SOURCE_USER='rsandbox',
SOURCE_PASSWORD='rsandbox',
SOURCE_AUTO_POSITION=1;
START REPLICA;PostgreSQL replication setup:
pg_basebackup -h 127.0.0.1 -p 16613 -U msandbox -D $DATA_DIR -R
pg_ctl -D $DATA_DIR -l $LOG_FILE startCompletely different commands, completely different protocols. But both fit the same CreateReplica(primary, config) signature. The MySQL version uses SQL + binlog positioning. The PostgreSQL version uses pg_basebackup (a physical backup of the primary’s data directory) followed by WAL streaming via primary_conninfo.
sequenceDiagram
participant CLI
participant Provider
participant Primary
participant Replica
CLI->>Provider: CreateReplica(primary, config)
Provider->>Primary: pg_basebackup
Primary-->>Provider: Physical data copy
Provider->>Provider: Write postgresql.conf + primary_conninfo
Provider->>Replica: pg_ctl start (connects to Primary's WAL stream)
Replica->>Primary: Stream WAL
Primary-->>Replica: Replication dataThe Capability System
Not all databases support the same features. PostgreSQL has no equivalent to MySQL’s Group Replication. dbdeployer handles this with two layers:
Topology Validation
Each provider declares what it supports:
// MySQL provider:
func (p *MySQLProvider) SupportedTopologies() []string {
return []string{
"single", "multiple", "replication", "group",
"fan-in", "all-masters", "ndb", "pxc",
}
}
// PostgreSQL provider:
func (p *PostgreSQLProvider) SupportedTopologies() []string {
return []string{"single", "multiple", "replication"}
}If you try to deploy Group Replication with PostgreSQL, you get an error before anything runs:
$ dbdeployer deploy replication 16.13 --topology=group --provider=postgresql
Error: topology "group" is not supported by provider "postgresql"Flavor Capabilities
Within MySQL-compatible databases, behavior varies by version and flavor. The capability system handles this:
// Can this version use mysqld --initialize?
HasCapability(flavor, "Initialize", version)
// Does this version support GTID?
HasCapability(flavor, "GTID", version)
// Should we use CHANGE MASTER or CHANGE REPLICATION SOURCE?
HasCapability(flavor, "ModernReplicationSyntax", version)This is why Percona Server, MariaDB, and VillageSQL all work without special-casing — they inherit MySQL’s capability map and override only where they differ.
Adding a New Flavor: VillageSQL as a Worked Example
VillageSQL is a MySQL drop-in replacement with extensions for custom types and VDFs (Vector Distance Functions). Adding it required changes to exactly 4 files:
1. Marker file constant (globals/globals.go):
FnVillagesqlSchema = "villagesql_schema.sql"2. Flavor detection (common/capabilities.go):
// In FlavorCompositionList, BEFORE the MySQL entry:
{
AllNeeded: false,
elements: []elementPath{
{"share", globals.FnVillagesqlSchema},
},
flavor: VillageSQLFlavor,
}3. Capability inheritance (common/capabilities.go):
var VillageSQLCapabilities = Capabilities{
Flavor: VillageSQLFlavor,
Description: "VillageSQL server",
Features: MySQLCapabilities.Features, // reuse everything
}4. Tarball name detection (common/checks.go):
VillageSQLFlavor: `villagesql`,That’s it. VillageSQL’s tarballs contain the same bin/mysqld, bin/mysql, and lib/libmysqlclient.so as MySQL. The unique marker is share/villagesql_schema.sql. When dbdeployer sees that file during unpacking, it identifies the flavor as VillageSQL. All MySQL sandbox lifecycle operations (init, start, stop, grants, replication) work unchanged because VillageSQL inherits MySQL’s capabilities.
graph TD
A[Unpack tarball] --> B{Detect marker files}
B -->|share/villagesql_schema.sql| C[Flavor: villagesql]
B -->|bin/mysqld + no unique markers| D[Flavor: mysql]
B -->|bin/mysqld + Percona markers| E[Flavor: percona]
C --> F[Inherit MySQL capabilities]
F --> G[Deploy with MySQL lifecycle]
D --> G
E --> GThe ordering in FlavorCompositionList matters: VillageSQL must come before MySQL because a VillageSQL tarball contains bin/mysqld. Without the marker check first, it would be misidentified as plain MySQL.
Cross-Database Constraints
When mixing providers, dbdeployer validates compatibility:
var CompatibleAddons = map[string][]string{
"proxysql": {"mysql", "postgresql"},
}ProxySQL can wire into both MySQL and PostgreSQL topologies. But you can’t deploy a PostgreSQL replica under a MySQL primary — the replication protocols are incompatible. The provider architecture makes these constraints explicit rather than implicit.
What’s Not Yet Migrated
The MySQL provider is currently a partial implementation. Most MySQL deployment still goes through the legacy sandbox package, which predates the Provider interface:
providers/mysql/mysql.go — CreateSandbox returns ErrNotSupported
sandbox/single.go — the actual MySQL deployment code
sandbox/replication.go — the actual MySQL replication codeThe PostgreSQL and ProxySQL providers are fully migrated. MySQL is next — we’re gradually moving functionality from the sandbox package into providers/mysql/ without breaking existing behavior.
Summary
The Provider architecture gives dbdeployer three things:
- Extensibility — new databases without touching core logic
- Type safety — topology validation before deployment starts
- Testability — each provider is independently testable with mock implementations
If you’re building a tool that needs to support multiple database backends, this pattern — interface for lifecycle, registry for discovery, capabilities for feature variation — is worth considering.
In the next post, we’ll use the PostgreSQL provider as a lens to explore the full story: deb extraction, config generation, streaming replication, and the limitations we ran into.
dbdeployer is an open source database sandbox tool maintained by the ProxySQL team. Star us on GitHub or read the docs.
Follow the GitHub repository for releases, or check back here for the detailed posts.
We are not just maintaining dbdeployer — we’re rebuilding it for the next era of MySQL and PostgreSQL development.