Amazon Aurora - Seamless Planned Failover with ProxySQL
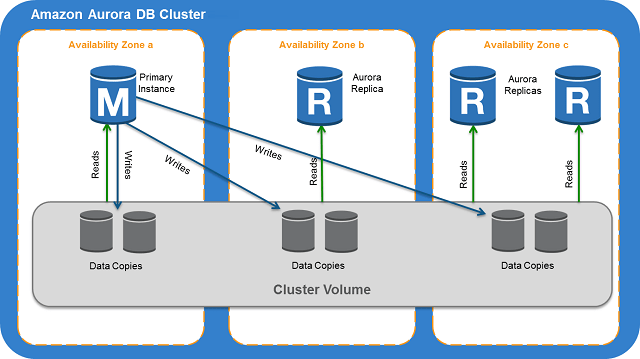
One of the more popular solutions for a DBaaS in today’s market is Amazon’s RDS / Aurora service. Historically Amazon RDS was quite popular however Aurora has been gaining ground especially due to the improved performance it provides, built-in automated capacity management and the easy to use high-availability features available. In particular, a failover in an Aurora cluster is easily achieved via the AWS console or using the AWS CLI. Connections are re-routed from the demoted primary instance transparently by Amazon by flipping the writer and reader endpoints canonical name record (CNAME).
There is however a drawback to this approach since existing connections are dropped and new connections can’t be made during the failover which takes around 30-60 seconds resulting in lost transactions unless applications are put into maintenance or stopped for the duration of the failover. It is important to note that if no Amazon Aurora Replicas are available for failover Amazon will create a new instance based on the existing and the process typically completes in around 15 minutes.
Seamless failover is highly sought after and this is easily achievable when combined with ProxySQL. Numerous articles available on the web already describe how ProxySQL can aid in unplanned failover using tools such as MHA and Orchestrator, this articles deals with planned failover which is a common question from many ProxySQL customers and community users. The following example illustrates the core Aurora ProxySQL configuration that can be used to test failover (additional configuration would be needed in a production setup e.g. definition of users / rules etc.):
- A pair of Aurora nodes (one writer and one reader) defined as the ‘proxysql-test’ cluster
- Each of the Aurora instances are added to separate hostgroups using the instance endpoints (not the reader / writer endpoints)
- A replication hostgroup in ProxySQL for the pair of reader & writer hostgroups specifying innodb_read_only for the check type
##### Initial configuration:
# Primary node is added to the writer hostgroup
insert into mysql_servers (hostgroup_id,hostname) values (1,'proxysql-test.cypraqtqmer0.eu-west-1.rds.amazonaws.com');
# Both Primary and Replica nodes are added to the reader hostgroup
insert into mysql_servers (hostgroup_id,hostname) values (2,'proxysql-test.cypraqtqmer0.eu-west-1.rds.amazonaws.com');
insert into mysql_servers (hostgroup_id,hostname) values (2,'proxysql-test-eu-west-1c.cypraqtqmer0.eu-west-1.rds.amazonaws.com');
# A replication hostgroup is created specifying "innodb_read_only" as the check type
insert into mysql_replication_hostgroups values (1,2,'innodb_read_only','This is the proxysql-test cluster');
# Load configuration to runtime
load mysql servers to runtime;
# Persist configuration to disk
save mysql servers to disk;Now that our ProxySQL instance is configured we can go ahead and perform a failover.
Typically the defined mysql_replication_hostgroup is used for unplanned failover, and since here we’ll be performing a planned failover we’ll need to temporarily remove it. We’ll also need to set the current Primary node to OFFLINE_SOFT allowing the existing statements to complete and to prevent any new statements from being sent to the Primary node. Once the running statements are completed we can perform the failover in AWS and wait for the new instance to become available - during this time ProxySQL will hold onto new connections coming in until the writer hostgroup becomes available again, these can possibly timeout due to a low setting for mysql-connect_timeout_server and mysql-connect_timeout_server_max. It is important to note that this approach works regardless of whether multiplexing is enabled / disabled.
After the failover is completed and the new Primary is available the host should be added to the writer hostgroup and the replication hostgroup should be added so that the ProxySQL instance is ready to handle unplanned failover again. The following script is a sample script that can be used for failover, again this is only for illustrative purposes and a more robust design should be implemented in a production environment:
#!/bin/bash
PROXYSQL_ADMIN_COMMAND="mysql -uadmin -padmin -h127.0.0.1 -e"
echo "Deleting replication hostgroup and setting server $1 to OFFLINE_SOFT"
$PROXYSQL_ADMIN_COMMAND "delete from mysql_replication_hostgroups;"
$PROXYSQL_ADMIN_COMMAND "update mysql_servers set status ='OFFLINE_SOFT' where hostgroup_id=1;"
$PROXYSQL_ADMIN_COMMAND "load mysql servers to runtime;"
# Here you should wait for the existing transactions to complete by polling the processlist
# until it clears before proceeding with the failover:
echo "Performing Aurora / RDS failover:"
aws rds failover-db-cluster \
--db-cluster-identifier proxysql-test \
--target-db-instance-identifier proxysql-test
echo "Waiting for server proxysql-test-eu-west-1c to become RW"
RC=1
while [ $RC -eq 1 ]
do
sleep 1
printf "."
RC=$(mysql -hproxysql-test-eu-west-1c.cypraqtqmer0.eu-west-1.rds.amazonaws.com -e"select @@innodb_read_only" -NB) > /dev/null 2>&1
done
echo "Reconfiguring ProxySQL to re-enable new writer node"
$PROXYSQL_ADMIN_COMMAND "insert into mysql_servers (hostgroup_id,hostname) values (1,'proxysql-test-eu-west-1c.cypraqtqmer0.eu-west-1.rds.amazonaws.com');"
$PROXYSQL_ADMIN_COMMAND "insert into mysql_replication_hostgroups values (1,2,'innodb_read_only','');"
$PROXYSQL_ADMIN_COMMAND "load mysql servers to runtime"
$PROXYSQL_ADMIN_COMMAND "save mysql servers to disk"
echo "Graceful failover completed!"If you have any questions please do not hesitate to contact us. Our performance and scalability experts will help you to analyze your infrastructure and help to build a robust and reliable architecture. We also offer consulting, long term support and training for ProxySQL.
Authored by: Nick Vyzas